

5月9日消息,中文通用大模型综合性评测基准SuperCLUE正式发布。
中文通用大模型基准(SuperCLUE),是针对中文可用的通用大模型的一个测评基准,它尝试在一系列国内外代表性的模型上使用多个维度能力进行测试。
它主要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况。包括但不限于:这些模型不同任务的效果情况、相较于国际上的代表性模型做到了什么程度、 这些模型与人类的效果对比如何?
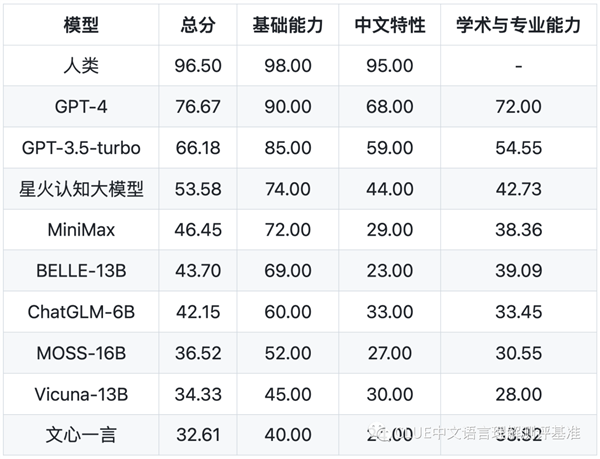
根据首个榜单显示,国内大模型中,近期发布的星火认知大模型最好,总分53.58分,与GPT-4相比有23个百分点的差距,与gpt-3.5-turbo在总分上有13个百分点的差距。
值得一提的是,讯飞星火认知大模型在对话、百科知识、角色模拟、计算能力、语义理解、逻辑推理方面,已经达到GPT 3.5平齐的水准。

在语义理解方面,讯飞星火认知大模型甚至得到100分的满分,超过GPT-4。
据了解,SuperCLUE评测榜单由三部分组成:总榜单、基础能力榜单、中文特性榜单,排行榜会定期更新,可点此访问.
基础能力:包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。
专业能力:包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。
中文特性能力:针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
总榜单
点赞
0
收藏
0
文章为作者独立观点不代表轻创业客+立场,未经允许不得转载。
 浙公网安备 33038202004573号
浙公网安备 33038202004573号